老僧三十年前未参禅时,见山是山,见水是水。及至后来,亲见知识,有个入出,见山不是山,见水不是水。而今得个休歇处,依前见山只是山,见水只是水。
—唐代青原惟信禅师

参禅的三重境界在 IT 技术圈同样适用,初学者感叹每个产品都如此精妙绝伦,追逐着最强的 IDE;老司机喜欢自比管乐指点江山,嘲讽着最好的语言。
当一切回归平淡,搞 IT 就是一份思想延伸和语言翻译工作,其中技术架构师就是一份古朴甚至无趣的工作。
我将架构师的工作总结出五条核心道理,这五条经验简单直白又深奥通透,算是对我 12 年 IT 工作的一个总结。

架构技术像机器人哄小孩一样简单
需求优化最重要:少查少写少依赖,Less is more
一个 IT 系统是多角色多模块分层分级的,像 OSI 模型上层应用简单依赖下层支撑,SOA 设计中同级角色也只看对方的接口。
各角色分工明确方便快速实现业务,但是给架构优化也埋下大坑,底层的盲目支撑是巨大资源浪费,平级调度协作也没任何弹性。
前端一个小逻辑需求会导致后端大规模联动,不同服务也没权限理解对方的内存数据,各个角色的工程师都只看自己的工作范围,这是正常又无奈的现状。
我们要搞架构设计最重要的就是砍需求,将上层应用的需求优化删减,让同级的业务能容错。
上层需求优化,即前端对后端少输入少查询多容错,而同级容错可以看做应用间的需求优化。
比如两个服务可以幂等重试就是好解耦,而 A 系统会等 B 系统等到死锁就是架构悲剧。
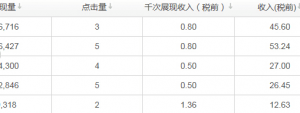
某电商 ERP 系统的用户点一次查询按钮,后台系统就锁库查询一次;实操过程中系统越慢用户就重复点查询按钮,而并行查询越多后台速度就更慢。
这种环境要搞架构优化,首先要理解自然人并不要求实时数据,ERP 客户端限制每 15 秒才能点一次查询按钮,在 Web 接入层限制每个 Session 每分钟只能查询一次,还可在数据库链接类库上做一层控制策略。
多媒体服务工程师最好的情人节礼物会是一个完美的播放器:
它可以自助容错选择 CDN可以主动预缓存下一分钟的点播内容可以完成私有解密编码工作可以和广告系统解耦独立加载可以在卡顿时更换线路和存储日志广告日志和卡顿日志都低速适时后台上传
抓住核心诉求,不该要的东西都不要
群集设计通用规则:前端复制后端拆,实时改异步,三组件互换
前端复制后端拆,实时改异步,IO-算力-空间可互换——要做架构就要上群集,而群集设计调优翻来覆去就是这三板斧。
前端是管道是逻辑,而后端是状态是数据,所以前端复制后端拆。前端服务器压力大了就多做水平复制扩容,在网站类应用上,无状态-会话保持-弹性伸缩等技术应用纯熟。
后端要群集化就是多做业务拆分,常见的就是数据库拆库拆表拆键值,服务拆的越散微操作就越爽,但全局操作开销更大更难控制。
实时改异步是我学的最后一门 IT 技术,绝大部分“实时操作”都不是业务需求,而是某应用无法看到后端和 Peer 状态,默认就要实时处理结果了。
CS 模式的实时操作会给支撑服务带来巨大压力,Peer 合作的实时操作可能会让数据申请方等一宿。
架构师将一个无脑大事务拆分成多个小事务,这就是异步架构,但拆分事务就跟拆分数据表一样,拆散的小事务需要更高业务层级上做全局事务保障。
在群集性能规划中,网络和硬盘 IO+CPU 算力+磁盘和内存空间是可以互换的,架构师要完成补不足而损有余的选型。
比如数据压缩技术就是用算力资源来置换 IO 和空间,缓存技术是用空间和 IO 来缓解算力压力,每个新选型都会带来细节上的万千变化,但每种变化都是符合自然规律有章可循的。
一个经典微机系统就是中央处理器+主存储器+IO 设备,这几个概念居然和群集性能规划是一一对应。

架构常见技巧就像空中华尔兹一样自然优雅
理解硬件天性:角色选型时要看硬件的天然特性
别让硬盘扛性能,别让内存保持久,别让网线扛稳定。
架构层软件技术已经足够成熟,所谓技术选型不如说是适应场景;在做具体角色选型时,最深度也最易忽视的原则是顺应硬件天性。
我的精神导师说过,如果一个服务依赖硬盘,那这个服务就不适合扛性能压力。
我经常将读写引到 /dev/shm,SSD 盘让很多细节调优聊胜于无,还让 Fat32 枯木逢春,个别队列和分布式存储在意硬盘的性能力,但都是应用了顺序读写内容,且不介意磁盘空间浪费。
别让内存扛持久和别让网线扛稳定,听起来很简单,但新手程序员总会犯低级错误,而犯错早晚要还技术债。
常规例子就是看新手程序是否有捕获各种异常的习惯,举个争议性例子,某些云服务设计者尝试给一个进程映射和绑定持久文件系统,请问一段内存如何绑定一块硬盘?

谈到天性,我总是想起流畅奔跑的小波妞
数据的产生和消失:数据不会凭空产生,但会凭空消失
数据不会凭空产生,计算机或者自输入设备获取数据,或者自其他数据源导入数据,而且原始数据的转化规则也要人类来定义。
我们要便捷轻巧安全可靠的获取数据,就要选好数据源,保障好传输路径,定义好数据变换规则。
在一个数据生命周期内,为了防止数据全部或部分凭空消失,数据的容错校验、关联复原、冷热备份和安全删除都要考虑到位。
在生僻业务的规划实施过程中,没人告诉我们该有哪些服务,我们只能靠摸透一个又一个访问逻辑图和数据生命周期,来摸索群集内有哪些角色和依赖关系。
架构师的核心技能包括画好访问逻辑和数据流量图,因为问题现状描述清楚了,问题就解决了一多半了。
一个好的业务访问逻辑图,不仅仅是几个圈圈几条线连起来,其信息量大到包罗访问过程的所有元素,也要详略得当高亮关键点。

咦?数据被拿走了。是啊,拿走了。好巧。我们还要做点什么吗?
各环节都不可盲信:容灾设计中都尽人事和听天命
整个 IT 系统中就没有可靠的组件,架构师既不能盲目信任撞大运,又不能无限冗余吓唬自己,而是在尽人事和听天命之间做好权衡。
比如 TCP 就是要建立可靠链接,而现在做性能优化的时候,大家又嫌 TCP 太过笨重了。
业务应用不可靠,如果该应用能快速重建也不阻塞其他应用,月级偶发的内存泄漏和意外崩溃都是可以接受的。
支撑性服务不可靠,对于大部分业务,预估一年都不丢一次数据,SLA 能到 99.95% 就可以了。
操作系统故障崩溃,现在商用系统内核都很稳定,一般故障都出在硬件驱动兼容性上,或者有些照本宣科的傻瓜乱改默认参数。
网络不稳定,内网通用的技术方案很成熟,少提复杂需求内网就能很稳定,我们最烦的是单条网线处于半死不活状态;IDC 的外网 SLA 默认就是 3 个 9,所以我说支撑性服务能到 99.95% 就已经很可靠了。
硬件不稳定,大部分架构师根本不懂硬件,只要不出硬件批次故障,架构师就可以将单点硬件和系统、服务绑在一起做可靠性设计。
人力误操作,我们招不到不出故障的人,我自己达不到不出错的标准。只要员工没有恶意破坏,出了大范围故障就是群集健壮性设计不到位,别让操作工给技术总监和架构师顶包。
监控和备份是运维的职责,但架构师需要帮忙确认目的正确性,别备份了半天废数据,监控只看 telnet80。

干活的角色和捣乱的角色一样多,甚至更多
结束语:架构之术繁琐,架构之道浅显
本文讲的是架构工作的“道”,对于架构之“术”并不提及。不同的业务系统的架构之术完全不同,能拿来汇总借鉴的只有这几条简单的道理。

心里不慌就飞起来吧
如果一个架构师只是炫耀具体优化架构的手法,却闭口不谈选型的道理,他们其实是在简单用公司业务尝试赌博。
如果我们有架构之道做思想支撑,即使接手全新业务类型,庖丁可以解牛也可以杀猪,我们一样能游刃有余心里不慌。
我曾经接手三种生僻晦涩的业务,按照本文的原理去拆解和规划,就没有什么特别难的。